Activity
Mon
Wed
Fri
Sun
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
What is this?
Less
More
Memberships
Learn Microsoft Fabric
Public • 5.3k • Free
3 contributions to Learn Microsoft Fabric

Sep 18 in
Lakehouse Table Creation
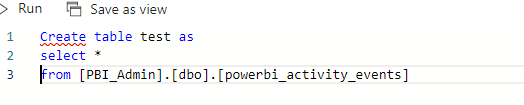
Hello. I am wondering if you can create a table from a view in the SQL Analytics endpoint in the Lakehouse. I am receiving errors around permissioning but I cannot tell how to fix the permissions. Here is the error message below: "The external policy action 'Microsoft.Sql/Sqlservers/Databases/Schemas/Tables/Create' was denied on the requested resource." Any help would be greatly appreciated.
0
1
New comment Sep 19

Jul 18 in
I need help transferring data from db to dataset in synapse
Hello everyone 👋, I'm working on a project where I need to dynamically copy all tables from a source SQL database to a dataset in Azure Synapse using pipelines. I'm looking for insights and ideas on how to achieve this effectively. Specifically, I'm interested in: 1. Dynamic Table Copy: How can I dynamically iterate through all tables in the source SQL database and copy them to the target dataset in Azure Synapse? 2. Pipeline Configuration: What are best practices for configuring Azure Synapse pipelines to handle dynamic table names and automate the data copying process?
0
2
New comment Jul 19
1 like • Jul 18
I feel like there is a lot of ways to do this activity, but one way I have solved this in the past is creating a metadata table in your sink database. In this case, that would be your Azure synapse warehouse. The metadata table can be created from sys views but can also be created manually. You probably want columns for fields such as "SourceTable_Schema", "SourceTable_Name", "SourceTable_Query", "DestTable_Schema", "DestTable_Name", "DestTable_StoredProcedure". Add columns as you see fit. I remember also having a column to determine if the table was a delta load or full load and if the table was active or inactive. Once you have this metadata table - let's call the table "etl.DataMovement", you can use a Lookup activity that returns a query with results from etl.DataMovement. Once you have those results in the Lookup activity, you can attach that activity to a "for each" activity and within the "for each" activity, you can run a copy statement. The copy statement will basically iterate over each table by selecting the "source query" and populate that data into your sink table. Obviously, there is a couple more steps in there with setting up permissions and linkages, but this was a great solution for me for nearly two years. The source queries were typically "Select * from <Source Table Name>. Depending on if you are going directly to a lake or to a warehouse, you may need to specify columns. But once you have those results in a source step, you can easily map them to your target.
Jul 18 in
Power BI Guidance
Hello everyone, I recently transitioned jobs from a smaller consulting firm (30 employees) that had a much more decentralized approach to reporting (individual and rather "custom" solutions for each client, typically controlled to a certain department of the business and very early into their power bi environment) to a much larger company (1300+) that has a centralized approach to reporting (one large enterprise solution that needs to satisfy the needs of different departments such as Sales & Marketing, Net Revenue, supply chain, finance, etc. and was hiring because of the growth that has occurred so dramatically in the span of two years). We are beginning our transition into Fabric and my team and I are trying to determine the best approach to an environment structure. We currently have a loose format of one workspace per department per sub department per environment (i.e., Finance - Accounting - Prod). However, I am not sure if this is the easiest and best way to maintain a solution, especially as we need to put a huge priority on CI/CD for power BI. - Should we have a workspace for each department or one workspace with a hierarchical folder structure? - Should we be establishing dev, UAT, and production or just two environments? - Should we be separating semantic models into their own workspace? - Still trying to understand best practices for GIT + CI/CD These are only a couple ideas that come to mind. There is so much to consider (which is sometimes overwhelming). I recently passed my DP 600 exam (Thanks, Will!) and have tried to better understand the new power bi file formats. I have been doing some research on this website around Power BI topics, but I wanted to create a post myself and ask for any and all resources/guidance on how to set up enterprise BI for such a large audience. Thanks for any feedback or resources. I am planning on putting together some videos and documentation around my process to hopefully help another developer who finds themselves in this situation in the future.
0
1
New comment Jul 18
1-3 of 3

@david-corrigall-4441
Love learning new things. Cannot wait to execute Fabric Solutions
Active 23d ago
Joined Jun 23, 2024
powered by