Activity
Mon
Wed
Fri
Sun
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
What is this?
Less
More
Memberships
Learn Microsoft Fabric
14.9k members • Free
Learn Power Apps
2.5k members • Free
4 contributions to Learn Microsoft Fabric

🚀
Apr '24 •
Fabric Q&A Call - View recording
Hey everyone, the third Fabric Q&A call recording has been published here. Thanks to everyone that attended!!

0 likes • Apr '24
So sorry I couldn’t attend today due to meetings. Ironically it was a meeting to advance Fabric within my organization. 🙂. I look forward to the recording.
🚀
Apr '24 •
Direct Lake vs Import Mode - SQLBI perspective
Marco Russo (who knows a thing or two about Power BI!) from SQLBI released this article recently about Direct Lake and Import mode. I would say I agree with a lot of what he mentioned; his views echoed the views that I have shared in this community and in my videos: just because Direct Lake is available to you now, doesn't mean you should use it in all scenarios! Just thought I'd send this reminder as it might impact your architectural decisions (and now my opinion has a bit more strength of conviction behind it, knowing that Marco Russo somewhat agrees 😊)
0 likes • Apr '24
Agreed Will. I appreciate these balanced points of view. I’m always hesitant to drink the kool-aid from the start until I understand the pros and cons and what uses case would benefit. I’m glad to see more discussion like this brought to light for the community.
1 like • Apr '24
Interesting comments in his X post as well for those interested. https://x.com/marcorus/status/1776537892807954865?s=46
🚀
Mar '24 •
New to the community? INTRODUCE YOURSELF! 😊
Hey everyone! This community is growing FAST. It would be great for any new members to introduce yourselves so that we can get to know each other... to understand your goals so that we can offer good support in your Fabric learning journey 🙌 So if you haven't already, please introduce yourself, with the aid of the following questions: 1. Which part of the world are you signing in from? 2. What's your current role? And your dream role in say 5 years time? 3. What attracted you to this community? 4. What excites you most about Fabric? 5. I'm really interested in learning more about _______ ? 6. Are you looking to get Fabric certified (DP-600)? Thank you for engaging and joining us on this exciting learning journey! 🙏 Will
2 likes • Mar '24
1. Monroe, Michigan 2. BI Engineering manager. I’m getting closer to retirement and would enjoy migrating to consulting. 3. What attracted me initially was the impressive video content you have created on Fabric! 4. The fact that managed self service for my team and our community of users now includes a much more complete set of features for analysis and development. 5. More about the abilities and limitations of the features from an architectural POV, to determine the right use of features for specific use cases. 6. Yes
2 likes • Apr '24
Yes. The freelance growth opportunities is one I forgot to add but a good one.
🚀
Mar '24 •
Fast Copy for Dataflows Gen2
So one of the announcements Microsoft was to the (much talked about) speed of getting data using a Dataflow; they added Fast Copy. Now, under the hood, I believe it leverages the same technology that Data PIpelines use (a lot quicker). There are a few limitations however: - You can't do much transformation on your data, so you can Extract and Load to a Lakehouse. Then transform it from there, or you can stage it to a Staging Lakehouse if you need to do more transformation. - Only .csv and .parquet files are supported (for getting file data) - you need to be ingesting 1M+ rows if using Azure SQL db Other important points to note: For Azure SQL database and PostgeSQL as a source, any transformation that can fold into a native query is supported. Let me know how you get on with this feature and whether it speeds up your Dataflow get data routines!
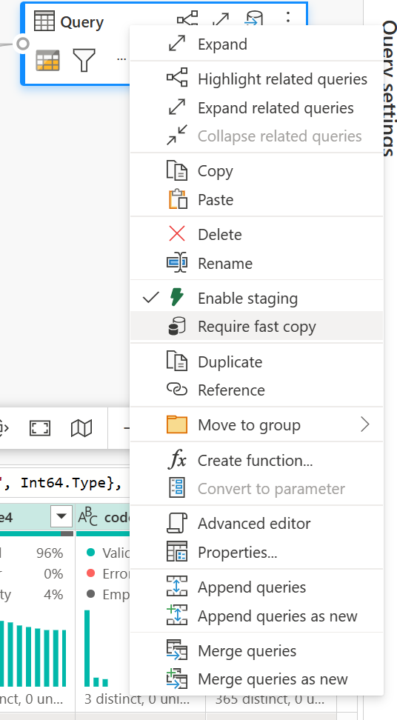
0 likes • Mar '24
I was disappointed that the initial roll out didn’t include fast copy from an on premise SQL Server
1-4 of 4

@bob-kundrat-3287
BI Engineering manager responsible for Fabric / Power BI for our community of users @ Carhartt.
Active 121d ago
Joined Mar 29, 2024
Powered by