Activity
Mon
Wed
Fri
Sun
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
What is this?
Less
More
Memberships
Data Alchemy
Public • 22.4k • Free
Advanced Data Science Society
Private • 101 • $99/y
530 contributions to Data Alchemy

21d ago in
Learning Together: Standard Deviation
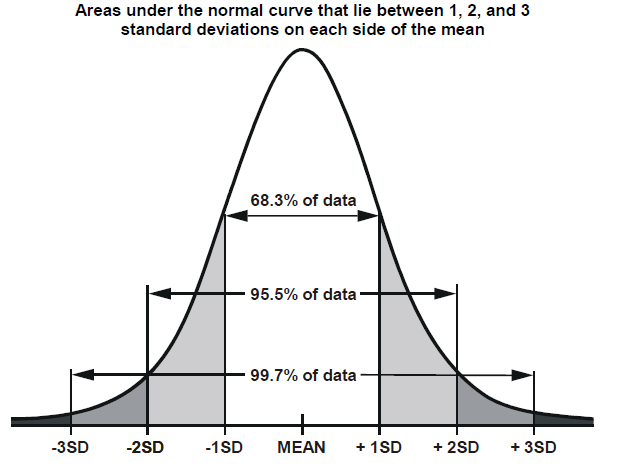
Hello, Data Alchemists! Welcome back to our journey of learning statistics together! In the last post, we explored variance and how it measures the spread of values in a dataset around the mean. Today, we're diving into Standard Deviation—a foundational concept that builds on variance and provides deeper insights into data variability. Standard Deviation Standard deviation is a measure of how spread out the values in a dataset are around the average (mean). It quantifies the typical distance of each data point from the mean, offering a more interpretable metric than variance since it’s expressed in the same units as the original data. How It’s Calculated Standard deviation is calculated as the square root of variance. Here’s the formula: - Variance (σ²) = Σ (xi - μ)² / N - Standard Deviation (σ) = √Variance This relationship allows standard deviation to convey the same spread information as variance but in a more intuitive way. What It Tells Us - High Standard Deviation: A high value means data points are more spread out from the mean, indicating greater variability. - Low Standard Deviation: A low value suggests data points are closer to the mean, reflecting more consistency in the values. Example Let’s compare the test scores of two different classes: - Class A: Scores are 85, 86, 87, 88, and 89. - Class B: Scores are 70, 80, 90, 100, and 110. In Class A, scores are tightly clustered around the mean of 87, resulting in a low standard deviation. In contrast, Class B’s scores vary widely, giving a higher standard deviation. This shows that students in Class B performed more variably compared to those in Class A. Why Use Standard Deviation? Standard deviation is widely used in statistics for several reasons: - Intuitive Interpretation: Because it’s in the same units as the data, it’s easier to relate to real-world measurements. - Normal Distribution Context: In a normal (bell curve) distribution, approximately 68% of values fall within one standard deviation of the mean. This gives a quick way to assess the concentration of values around the mean.
14
11
New comment 1d ago
0 likes • 12d
@Sean Wooten 😁
0 likes • 2d
@Samuel Allen lol, no I am not. I am learning and sharing at the same time in order to get the ideas clearer in my mind.
Oct 26 in
Free Coding Support: Python, R, and More – Let’s Connect!
Hi fellow Data Alchemist! I hope you're all doing well. I'm here today to offer a helping hand to anyone who might be struggling with Python, R, or programming logic. I’m really passionate about explaining concepts clearly and want to get even better at it, so I’m offering my support for free, just because I love doing this! If you're stuck on something or have any questions, don’t hesitate to reach out. You can message me privately, and if needed, we can even hop on a call to figure things out together. I’m really looking forward to helping out, so feel free to get in touch! Wishing you all an amazing weekend. 😊 Best, Ana
32
29
New comment 3h ago
0 likes • 2d
@Samuel Allen of course 😉.
0 likes • 2d
@Abdul Latheef Your welcome
6d ago in
Exclusive Opportunity for Data Scientists: Join for Free Before It's Paid
Hi everyone! I wanted to share a Skool group I came across that might interest you. The group is led by someone with experience at both Apple and Google, and it’s specifically designed for data scientists. Currently, there are only 55 members. From what I understand, the group will transition to a paid model after reaching 100 members, but those who join early will have free access 😉. This could be a great opportunity for anyone looking to join early! The group is called Advanced Data Science Society, and here’s the owner's profile: LinkedIn Happy learning everyone!!! @Brandon Phillips @Viktorija Trubaciute
6
5
New comment 12h ago
1 like • 3d
@Viktorija Trubaciute 😉

6d ago in
Exploring the World of Data Alchemy Together
Hey everyone, It’s exciting to finally be a part of this incredible Data Alchemy community! Data is reshaping every corner of the world, and what excites me most is how this group brings together such diverse minds—from analysts and scientists to engineers and enthusiasts—each solving unique problems in their domains. To kick off meaningful conversations, I’d love to hear more about you: - What’s your current role or project focus in the data space? - What skills or tools are you working on mastering? - And if you could snap your fingers and gain expertise in one area of data, what would it be? For me, it’s always inspiring to see how data professionals are tackling real-world challenges, whether it’s optimizing supply chains, driving AI innovation, or delivering insights that change business decisions. Let’s use this thread to share, connect, and uncover how we can help each other grow. Who knows? We might even find opportunities to collaborate or exchange resources that level up our journeys. Does anyone wish to connect? I am available here https://www.linkedin.com/in/kunal-soni/ Looking forward to learning about your experiences and insights! Cheers, Kunal https://www.mciskills.com/
3
2
New comment 4d ago
1 like • 4d
Hi Kunal! Welcome to Data Alchemy! Answering your questions: I’m an intern data scientist at an HR analytics company. At work, we use R, while I use Python for my personal projects. Currently, I’m studying a bit of everything—from maths and statistics to improving my coding skills and exploring machine learning.
24d ago in
Studying Together: Understanding Measures of Central Tendency
Hi fellow Data Alchemists, I’m writing here with the goal of studying together the essentials we need to know if we want to become Data Scientists or work with Machine Learning. I’m considering creating a series of posts covering Statistics, Probability, and maybe even some Math needed for Machine Learning. I’m not an expert, so I’ll be gathering information from the web, I'll write the post and I'll ask ChatGPT to correct me. My idea is to create some accountability for myself while sharing my studies with all of you. Today, I thought I’d start with the basics: Measures of Central Tendency. As the title suggests, "Central Tendency" should already give us a hint about what this is about, right? If you're not sure, it’s simply a fancy term for describing the mean, median, and mode. So, what are Measures of Central Tendency? They’re key statistical tools that help us summarize and understand the central point of a dataset. These measures are especially useful in data science for interpreting data distributions and providing meaningful insights into the general behavior of the data. The three primary measures, mean, median, and mode, each give us a unique perspective on this “center.” - Mean: The mean is calculated by summing up all data points and dividing by the count of those points. It’s useful when data is symmetrically distributed, as it represents the expected value. However, it’s sensitive to outliers, so in skewed distributions, it might not accurately represent the center of the data. - Median: The median, or the middle value when data is ordered, is especially valuable in skewed distributions or when there are outliers. Since it reflects positional rather than magnitude-based centrality, it often provides a more robust measure of central tendency than the mean in non-normal distributions. - Mode: The mode, or the most frequently occurring value, is useful in categorical data or multimodal distributions. It offers insights into the most common category or value in the dataset, which can be particularly important for understanding customer preferences, product popularity, or common patterns in discrete data.
21
20
New comment 4d ago

1 like • 6d
@Samuel Allen Thanks
0 likes • 4d
@Michael Dambock Thanks! I'll do it this weekend 😉
1-10 of 530

@ana-crosatto-thomsen
Passionate about data science, exploring the frontiers of Data and AI. Dedicated to crafting innovation, one line of code at a time!🌟
Active 58m ago
Joined Sep 11, 2023
INFJ
Brazil
powered by